人脸识别(2)-反向传播(BP)
反向传播(BP)
上一篇文章讲了感应器,将把这些单独的单元按照一定的规则相互连接在一起形成神经网络,从而获得了强大的学习能力。称之为反向传播算法
反向传播算法:计算输出层结果与真实值之间的偏差来进行逐层调节参数(逐层条件参数一般用到梯度下降算法)
首先我们得明白神经网络的参数训练是一个不断迭代的过程
当网络结构已知时,参数训练的过程如下: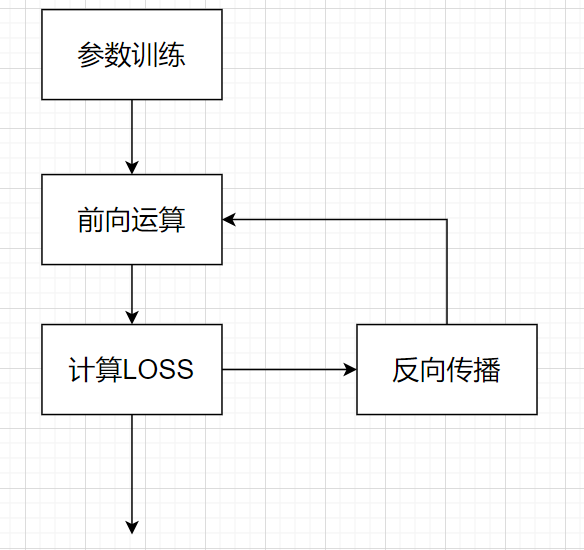
通过给定的数据和其对应的便签作为输入进行训练,通过前向运算计算出实际结果,实际结果与标签的差距我们称之为loss(这里loss的形式是多种多样的,比如一次方,二次方等等),通过梯度下降算法不断添加参数,我们期望不断地降低loss。当loss最小时,我们找到了一组最优的参数组合。
参数优化是神经网络中非常重要的一块部分,我们一般是通过导数和学习率来优化,这个部分我们之后再讲。
我们来看一个参数优化的函数:
loss = $min_W||WX - Y||^2$
其中W为参数项,WX为实际结果,Y为样本X的标签,这个函数计算了真实结果与预测结果的差异,我们希望其越小越好。
怎么求其最小呢,我们可以直接求解,对上述函数对W进行求导,此次X,Y为已知项。
也可以利用梯度下降的算法,下降重大讲解一下梯度算法
梯度
梯度:函数在A点无数个变化方向中变化最快的那个方向。(梯度生而最快)
梯度就定义为偏导向量的方向。沿着偏导向量方向的方向导数f(x,y)能够取得最大值。(记不得的可以翻大学高数课本)
因此我们在不断的迭代计算中,每一次沿着负梯度方向进行更新参数,就能够达到最低点。
比如下面的一元函数凹曲线:
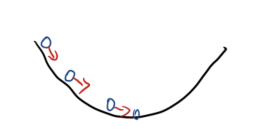
如果我们沿着函数导数方向走,可以走到最低点。
当然如果函数不是标准的函数:
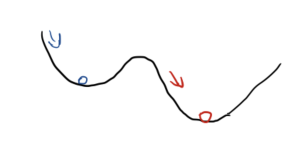
会出现多个最低点
梯度下降算法
梯度下降算法 就是沿着导数下降的方向,进行参数优化
公式:$x_{new} = x_{old} - \eta \Delta f(x) $
其中,$\Delta$是梯度算子,$\Delta f(x)$就是指的梯度。$\eta$是步长,也称作学习率。(梯度上升算法:顾名思义,把减号改成加号即可)
参数优化中,选择合适的步长/学习率 非常重要
如果步长$\eta$太大,会出现
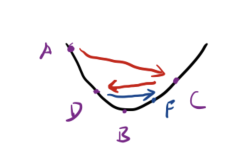
如果从A点出发,会错过B点,到达C点,再到达D点,再到达F点。这种情况反映到loss上是,loss不断震荡,无法趋于最小。
反正太小也不好,那样学习效率太低,需要过多的训练,所需时间过长。所以保持一个合适的步长非常重要。
一般步长一开始0.01到最后调整到0.001(这只是举个通用的例子,还有许多情况)
局部最优解
我们必须明白使用梯度下降算法,并不能保证一定能找到全局最优解。很可能是局部最优解,关键是优化函数的问题,初始化值会影响找到的最优解
反向传播就讲到这了,后面会讲卷积神经网络相关知识。
本篇文章到这里就结束啦,如果喜欢的话,多多支持,欢迎关注!