哈喽,大家好,我是呼噜噜,加更一期,昨天晚上我还在外网快乐的冲浪,结果常用的网站,除了google家的以外,就陆续出现这种情况
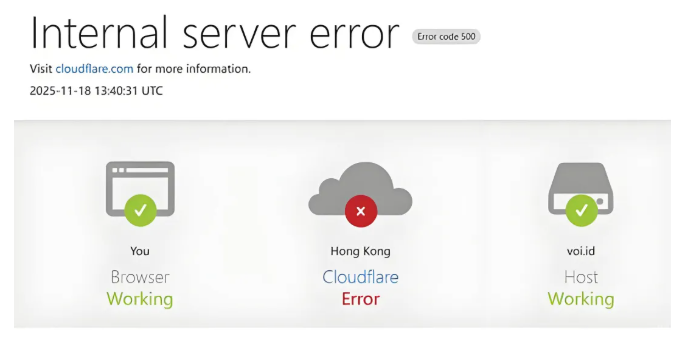
然后我想打开chatgpt来问问它,什么原因?给我一点灵感和解决的方向,结果:

好家伙!

实在困,就睡了。今早一看,背后的元凶原来是Cloudflare,这个事闹的比我预料的还要大得多
在2025年11月18日,Cloudflare突发大规模服务中断,就是我们常说的崩了!

这次宕机持续了近 6 个小时,这一崩,直接导致全球近半数互联网服务受到影响,包括社交媒体、人工智能平台、在线工具及游戏服务等大量网站,出现"500 Internal Server Error"访问错误或提示加载失败
故障监测平台Downdetector,显示短时间内短时间内激增至数万份,受影响的服务名单堪称“互联网名人录”:
- 社交与AI平台:Twitter(X)、OpenAI
- 流媒体与娱乐:Spotify
- 在线游戏:《英雄联盟》(League of Legends)、《瓦洛兰特》(Valorant)
- 基础设施:AWS、Google Cloud部分服务
- .......等等,海量的网站和服务
为啥Cloudflare出事,波及面这么广?
你可能也听说过 Cloudflare,或者至少感受过它的存在。今天它又一次成了话题——因为每次它一出问题,世界上就有数不清的网站跟着“挂掉”。
它是全球最大的 CDN 和安全服务提供商之一,通过其遍布全球的数据中心网络处理请求。它会选择最快的路由将内容送达用户,并以最接近用户的速度呈现内容。它为数百万网站处理互联网请求,平均每秒处理 8100 万个 HTTP 请求。

普通人碰到它最常见的场景就是,下方的这个人机校验按钮:
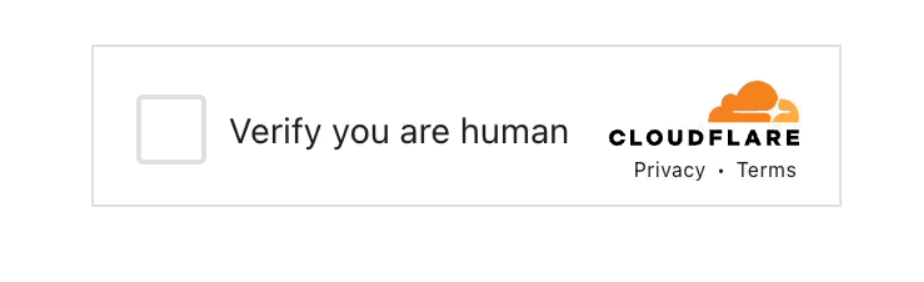
眼熟吧,相信很多人都遇到过,这其实就是Cloudflare给你访问的网站,提供的一种保护服务
在我们技术圈里,很多人把 Cloudflare 叫做“赛博菩萨”。因为它太慷慨了,慷慨得让人觉得像在做慈善。
对我们很多做网站的人来说,流量和安全,尤其是防御DDoS攻击,通常都是按秒计费的“奢侈品”。一次攻击,可能就让一个小站瞬间瘫痪,甚至直接关停。
但 Cloudflare 不一样。它提供了一套真正能用的免费套餐——扛攻击不限流量、全球CDN加速、还有那个让人安心的小绿锁HTTPS加密……
全都免费给你用!

正是因为这些,无数个人博客、初创团队、拿不出预算的小站,才得以在今天的互联网上活下来。没有它,一次攻击可能就是终点;有了它,哪怕你是一个人,也能拥有接近大厂级别的防护。
这大概就是“赛博菩萨”这个名字的由来——它不声不响,护着成千上万普通人建的网站,让他们不被流量冲垮、不被恶意击倒。
也正因如此,一旦 Cloudflare出现故障,比如昨天的这次宕机,导致半个互联网就像突然停电,直接瘫痪,堪比世界大战!
官方的故障报告
我看网上有人传这张图片:

这条帖子是fake news,这位博主是蹭热度,整活的,去年整活的帖子也被扒出来了~~
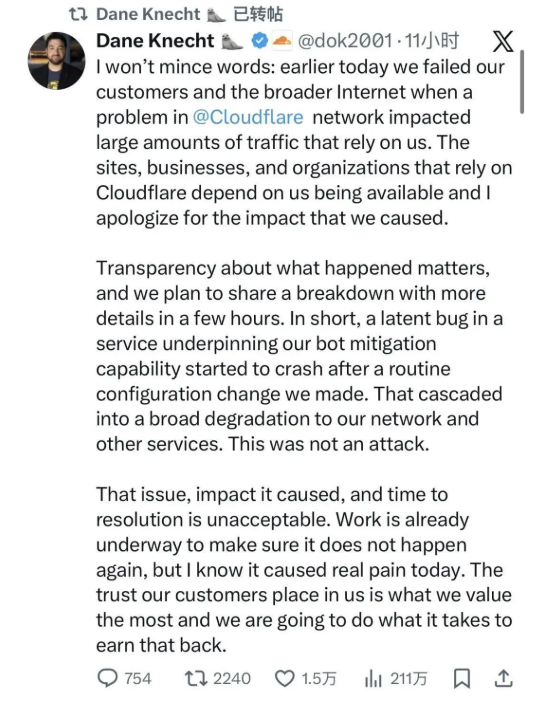
我们还是以官方的回应为准: Cloudflare首席技术官戴恩·克内希特(Dane Knecht)在X上公开致歉,“今天早些时候,Cloudflare网络出现问题,影响了大量依赖我们的流量,我们辜负了我们的客户和整个互联网。”
这次不是黑客攻击!根据最新的报告,官方明确说:不是 DDoS,不是入侵,是内部配置问题。我们来具体看一下:
- 在
11月20日19.05,Cloudflare团队对其一个ClickHouse数据库系统的权限管理进行了变更。这本是一个常规操作,但意想不到的是,这次变更导致了 SQL 查询结果出现了重复行(Duplicate Rows) - 数据异常:此变更导致一个用于生成
Bot Management(机器人管理)系统“特征文件”的数据 查询行为发生变化。该查询开始返回大量重复数据,使得生成的特征文件体积翻倍,瞬间暴增到了 200 个以上 - 系统限制:
Cloudflare核心代理软件对特征文件的大小有预定的内存分配限制(上限为200个特征)。翻倍后的文件大小也就超出了此限制! - 服务崩溃:当超大的特征文件被分发到全球网络节点并加载时,又因为处理流量的核心 Rust 代码中包含一个硬编码限制:
features.checksum的处理逻辑预设特征数不超过 200(为了性能优化)。
Cloudflare故障报告里,专门指出了导致这次宕机的那行 Rust 代码:
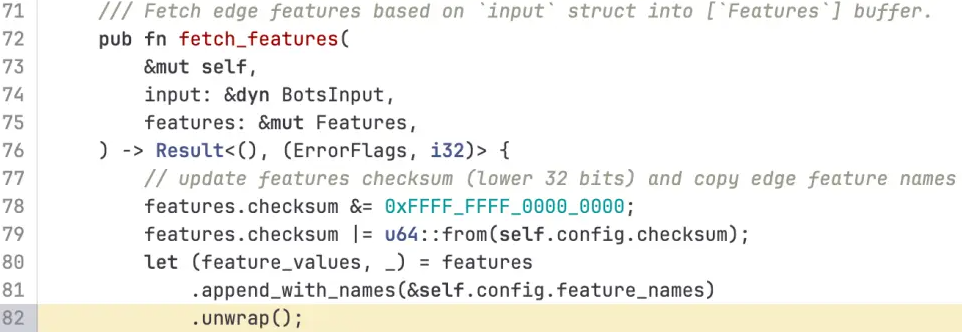
这块比较专业一点,但呼噜噜也懂rust呀,我给大家讲解一下。当特征文件体积翻倍,当超过逻辑预设特征数200的限制时,代码触发了.unwrap(),由于使用了unwrap()他会直接导致进程 Panic,也就是恐慌
最终导致核心代理进程崩溃,无法正常处理用户请求,从而返回大量HTTP 5xx错误。最麻烦的是: 这个错误文件每 5 分钟会自动重新生成并在网络中传播,导致问题反复出现,加大了排除的难度
小刀割屁股,开了眼了,这么离谱的嘛!敢在生产环境使用.unwrap(),还是这么大公司
不应该用?来捕处理错误,既方便也强大,实在不行except也行啊,起码打印点错误信息

咳咳,请我过去,我可以避免这种情况,我直接在cargo.toml中添加:
[lints.clippy]
unwrap_used = "deny"
expect_used = "deny"它是 Rust 1.80+ 新增的 lints 统一配置方式,用来在 整个项目范围内 强制禁止 unwrap() 和 expect() 的使用。

此次11月的宕机并非孤立事件。我简单回顾2025一整年,发现全球云基础设施宕机世界已经发生了好多起,一起比一起严重,比如:
- 2025年6月12日,Cloudflare与Google Cloud发生了罕见的并发基础设施故障,好多人不清楚,但Cloudflare今年早期也发生了故障
- 2025年10月20日,亚马逊AWS出现持续故障,导致超过一千个网站和在线应用数小时瘫痪
我感觉云服务并没有厂家宣传的那么安全,故障要么不出现,一出现就是波及全球互联网的大地震!
现代互联网,也有其脆弱性,所以更需要大家的守护
本文到这里就结束啦,感谢你的阅读,关注我,获得更多干货!我们下期再见
如果你对此次事件有任何想法,欢迎在下方留言!
作者:小牛呼噜噜
本文到这里就结束啦,感谢阅读,关注同名公众号:小牛呼噜噜,防失联+获取更多技术干货